
robots.txt یک فایل متنی است که در مسیر اصلی فضای سایت یا روت دایرکتوری (Root Directory) قرار میگیرد. فایل robots.txt وظیفه معرفی بخشهای قابل دسترسی و بخشهای محدود شده برای دسترسی رباتها و خزنده های گوگل را برعهده دارد. بنابراین با درج دستورات خاصی در این فایل، میتوانید قسمت های مد نظرتان را برای ربات های موتورهای جستجو مشخص کنید تا فقط آن ها را ایندکس کنند.
بهبود عملکرد سایت و مدیریت لینک ها از دیگر مزایای استفاده از فایل robots.txt است. برای آشنایی بیشتر با نحوه عملکرد و ساخت این فایل متنی با گرشا همراه شوید و ادامه مقاله را از دست ندهید.
robots.txt چیست و چرا اهمیت دارد؟
robots.txt فایلی است که در روت اصلی هاست قرار می گیرد. بنابراین آدرس دسترسی به این فایل به صورت زیر خواهد بود :
www.Yourwebsite.com/robots.txt
چنانچه سایت شما فایل متنی فوق را نداشته باشد، رباتهای موتورهای جستجو می توانند به تمام صفحات سایت شما دسترسی داشته باشند. بنابراین تمام محتوای سایت را ایندکس می کنند.
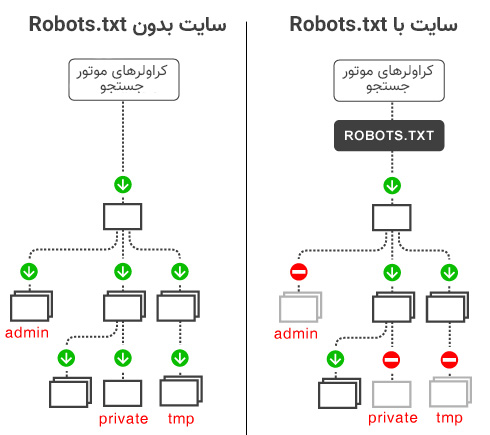
اگرفایل متنی با فرمت استاندارد و صحیح ایجاد نشده باشد و یا اطلاعات و دستورات داخل آن قادر به شناسایی نباشند، ربات های موتورهای جستجو باز هم می توانند به اطلاعات دسترسی داشته باشند. این بدان معناست که ربات ها به صورت پیشفرض بررسی و ایندکس تمام قسمت های سایت را انجام می دهند مگر اینکه به صورت دقیق در فایل robots.txt دستوری دریافت کنند و تغییر رفتار دهند.
مدیریت دسترسی موتورهای جستجو
به نظرشما چرا نباید بعضی از صفحات یا فایلهای سایت ایندکس شوند؟
پاسخ: گاهی ایندکس شدن و معرفی یک صفحه یا فایل از سایت در موتورهای جستجو منجر به نتایج نامناسبی می شود. به عنوان مثال انتشار مطالبی که برخی از قوانین و مقررات موتورهای جستجو را نقض می کند و یا امکان انتشار محتوای آن به صورت عمومی وجود ندارد را می توان به کمک فایل robots.txt مدیریت کرد و دسترسی موتورهای جستجو را محدود ساخت.
بهبود عملکرد سایت
سایت ها به صورت مداوم توسط موتورهای جستجو مورد بازدید و بررسی قرار می گیرند. هر ربات ابتدا اطلاعات را بررسی و سپس ایندکس می کند. بنابراین تمام قسمت های سایت ارزیابی می شوند. بدیهی است ترافیک بالای کاربران و حجم بالای ربات ها می تواند مشکل ساز باشد. استفاده از فایل robots.txt راه حل این مشکل است. و می توان دسترسی ربات های موتورهای جستجو را به قسمت های مشخص شده که اهمیت زیادی در سئو ندارند، محدود کرد.
با این روش نه تنها سرور سایت با ترافیک کم تری فعالیت خواهد کرد، بلکه مراحل بررسی و جمعآوری اطلاعات و سپس ایندکس کردن آنها توسط رباتها نیز با سرعت بالاتری انجام خواهد شد.
مدیریت لینک ها
مدیریت لینکها وURL توسط robots.txt امکان پذیر است. مخفیسازی آدرس صفحات یا URL Cloacking نوعی تکنیک سئو برای پنهان کردن آدرس صفحات از دید کاربران و یا موتورهای جستجو است.
می توان گفت لینکهای مربوط به Affiliate Marketing یا سیستم همکاری در فروش بیشترین استفاده را از فایل متنی مذکور دارند. با مدیریت لینکهای ایجاد شده در سیستم همکاری در فروش می توانید آدرس آن ها را مخفی کنید.
نکته: مخفیسازی آدرس صفحات یا URL Cloacking حتما بایستی توسط افراد ماهر انجام شود. در صورتی که به درستی پیاده سازی نشود، با نقض قوانین موتورهای جستجو شامل جریمه گوگل می شوید.
آیا گوگل همچنان از دستورات فایل robot.txt پیروی میکند؟
قبل از هر چیز باید به این سوال مهم پاسخ دهیم که آیا در سال ۲۰۲۱ دستورات این فایل توسط گوگل و سایر موتورهای جستجو پیروی می شود یا خیر.
گوگل به صورت رسمی اعلام کرده است که از سپتامبر ۲۰۱۹ ربات های گوگل از دستور نوایندکس فایل robot.txt پیروی نخواهند کرد و وب مستران برای ایندکس نشدن صفحات خود باید از راهکارهای جایگزین استفاده کنند.
In the interest of maintaining a healthy ecosystem and preparing for potential future open source releases, we’re retiring all code that handles unsupported and unpublished rules (such as
noindex) on September 1, 2019.
همچنین گوگل در توئیتر رسمی خود اعلام نموده است که:
Today we’re saying goodbye to undocumented and unsupported rules in robots.txt
امروز ما با قوانین پشتیبانی نشده و غیر مستند در فایل robots.txt خداحافظی می کنیم.
در حال حاضر استفاده از noindex در متا تگ Robot در بخش هد صفحات، موثرترین راه برای حذف URL ها از ایندکس و کراول شدن است. البته تفاوت اصلی در این است که با استفاده از فایل robot.txt می توانستیم کل سایت و یا کل یک دسته بندی را نوایندکس کنیم در حالی که با متاتگ robot باید صفحات را تک تک noindedx نمود.
<meta name=”robots” content=”noindex, nofollow”>
همچنین با پنهان کردن اطلاعات و محدود کردن آن برای کاربران لاگین شده به سیستم و یا استفاده از یوزرنیم و پسورد برای مشاهده اطلاعات و محتوای آن، می توان موجب حذف شدن و ایندکس نشدن آن از فهرست گوگل شد.
با کمک ابزار Remove URLs در سرچ کنسول گوگل نیز می توان یک url را به صورت موقت از نتایح جستجوی گوگل حذف نمود.
دستورات robots.txt چیست؟
مهمترین دستورات این فایل متنی شامل User-agent ، Disallow ، Allow ، Crawl-delay وSitemap است.
User-agent:
با این دستور می توان به ربات خاصی و یا به تمام ربات ها اجازه دسترسی را داد یا محدود کرد. بنابراین ربات بعد از ورود به صفحه، و قبل از بررسی صفحه، فایل robots.txt را چک می کند.
User-agent: * به معنای در دسترس بودن تمام قسمت های سایت برای تمام ربات های موتورهای جستجو است. چنانچه قصد دارید اطلاعات صفحه فقط برای ربات خاصی در دسترس باشد، به جای * نام ربات را بنویسید. مثلا در کد User-agent: Googlebot فقط ربات گوگل حق دسترسی به اطلاعات را دارد.
Disallow & Allow:
این دستور برای مشخص کردن قسمت هایی است که باید توسط User-agent بررسی و ایندکس شوند. کد Allow به منزله ایجاد دسترسی و کد Disallow به منزله محدودسازی دسترسی رباتها مورد استفاده قرار می گیرد. دستور “Allow: /” به معنای اجازه بازدید، بررسی یا ایندکس توسط ربات ها است. اما با درج دستور “Disallow: /” در فایل robots.txt به رباتها اعلام میکنید که آنها نباید هیچ صفحهای از این سایت را بازدید، بررسی یا ایندکس کنند.
Sitemap:
یکی از روش های ساده برای ثبت کردن نقشه سایت در موتورهای جستجو، درج دستور مربوط به نقشه سایت در robots.txt است. بااین روش برای موتورهای جستجو مشخص می کنید که فایل XMLنقشه سایت شما را از چه مسیری پیدا کرده و به آن دسترسی داشته باشند. برای این کار کد دستوری زیر را در فایل robots.txt اضافه کنید :
Sitemap: https://example.com/sitemap.xml
Crawl-delay:
نرخ تاخیر یا Crawl-delay موجب می شود تا رباتهای موتورهای جستجو برای بررسی و ایندکس کردن صفحات شما به نوبت، برای زمان مشخص شده توسط شما صبر کنند. کاهش تعداد درخواستهای پیاپی رباتها به سرور سایت، هدف اصلی نرخ تاخیر است. کد crawl-delay: 10 به این معناست که ربات های موتورهای جستجو Yahoo و Bing بعد از هر ایندکس به مدت ۱۰ ثانیه صبر کنند و سپس صفحه دیگری را ایندکس کنند.
اما استفاده از همین کد برای موتور جستجوی Yandex به این معناست که هر ۱۰ ثانیه یک بار به کل صفحات سایت دسترسی پیدا خواهند کرد.
نکته: این دستور روی ربات گوگل یا Googlebot قابل استفاده نیست. برای فعال کردن این قابلیت در گوگل باید از Google Search Console نرخ زمان مربوط را از بخش تنظیمات سایت مشخص کنید.
نحوه ساخت فایل robots.txt
برای اینکه متوجه شوید قبلا فایل متنی در سرور سایت شما ایجاد شده است یا نه آدرس www.example.com /robots.txt را تایپ کنید. در صورتیکه ارور ۴۰۴ به شما نشان داده شد، یعنی این فایل قبلا ساخته نشده است.
برای ساخت یک فایل متنی، از طریق Notepad ویندوز یک فایل txt بسازید و آن را با نام robots ذخیره کنید. سپس دستورات مدنظر را درون آن قرار داده و فایل را ذخیره سازی کنید. در نهایت، فایل آماده شده را از طریق FTP یا فایل منیجر کنترل پنل هاست در روت اصلی سایت آپلود کنید.
اما اگر با کدهایی که در بالا معرفی کردیم روبرو شدید، بدان معناست که سایت شما این فایل متنی را دارد. برای ویرایش فایل robots.txt باید از طریق FTP و یا کنترل پنل هاست سایت خود، به قسمت مدیریت فایل رفته و در روت اصلی هاست فایل robots.txt را پیدا کنید. سپس ویرایشات لازم را انجام دهید و آن را جایگزین فایل متنی قبلی کنید.
فایل robots.txt در وردپرس چگونه است؟
وردپرس به صورت پیشفرض یک فایل متنی robots.txt دارد. این فایل متنی را نمی توان به صورت مستقیم پیدا و آن را ویرایش کرد. یک روش که بتوان این فایل را مشاهده کرد باز کردن آدرس مستقیم آن در مرورگر http://www.example.com/robots.txt است. برای ویرایش این فایل می توانید به چندین طریق عمل کنید. اگر از افزونه Yoast SEO استفاده می کنید، می توانید فایل robots.txt را در قسمت داشبورد افزونه ایجاد و ویرایش کنید. بدین منظور به منوی ابزارها در زیرمجموعه منوی سئو رفته و روی گزینه File editor کلیک کنید. با کلیک بر روی گزینه Create robots.txt می توانید اقدام به تولید و ویرایش محتوای روبات فایل کنید.
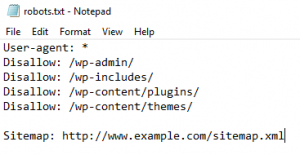
دستورات زیر به صورت پیشفرض در فایل robots.txt قرار دارند:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
بنابراین رباتها به صفحه admin-ajax.php دسترسی دارند. برای غیرفعال کردن این حالت، به تنظیمات وردپرس در صفحه wp-admin رفته و گزینه Search Engine Visibility را فعال کنید تا دسترسی تمامی رباتها به سایت شما مسدود شود.





")
")



")





")
")






")
")


